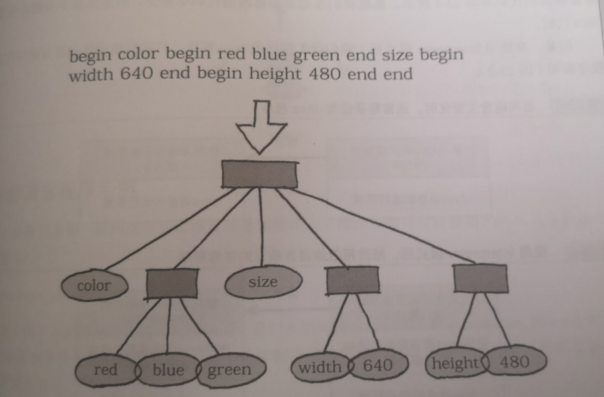
语法规则也是类
设计模式之Command模式
命令也是类
设计模式之Proxy模式
只在必要时生成实例
设计模式之Flyweight模式
享元模式(Flyweight Pattern)是一种结构型设计模式, 它摒弃了在每个对象中保存所有数据的方式, 通过共享多个对象所共有的相同状态, 让你能在有限的内存容量中载入更多对象。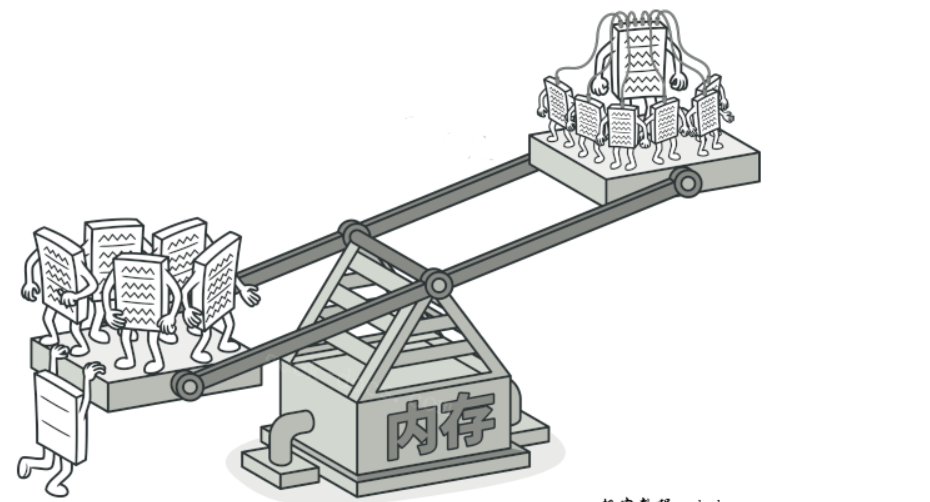
ps:动态规划是嘛?
设计模式之State模式
状态模式(State Pattern)是一种行为设计模式, 让你能在一个对象的内部状态变化时改变其行为, 使其看上去就像改变了自身所属的类一样。状态模式允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。其别名为状态对象(Objects for States),状态模式是一种对象行为型模式。
设计模式之Memento模式
备忘录模式用于保存和会复发对象的状态.比如在玩游戏的时候有一个保存当前闯关的状态的功能,会对当前用户所处的状态进行保存,当用户闯关失败或者需要从快照的地方开始的时候,就能读取当时保存的状态完整的恢复到当前的环境,这一点和VMware上面的快照功能很类似.
设计模式之Observer模式
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。
观察者模式又叫做发布-订阅(Publish/Subscribe)模式、模型-视图(Model/View)模式、源-监听器(Source/Listener)模式或从属者(Dependents)模式。
设计模式之Mediator模式
Mediator模式又称为仲裁者模式或者中介者模式,所起的作用是仲裁和中介,帮助其它类之间进行交流。在仲裁者模式之中,我们要明确两个概念,那就是仲裁者(Mediator)和组员(Colleague),不管组员有什么事情,都会向仲裁者汇报,仲裁者会根据全局的实际情况向其他Colleague作出指示,共同完成一定的逻辑功能。
设计模式之Facade模式
设计模式之Chain of Responsibility模式
